

准确和精确在汉语里面是近义词,我们在口语中是可以混用的,英语中也如此,accurate和precise人们也是随性而用,脱口而出。可是,既然有两个词存在,而没有在文字演化的长河中消亡其中一个,就说明它们还是有微妙的不同。事实上,准确和精确绝对不是同一个概念,它们在工程学、统计学以及其他许许多多的科学中都被严格的区分,对于互联网运营分析这么新兴的学科而言,也完全如此。
我们先看看准确和精确到底有什么不同,然后再看看分析工具能够做到准确还是精确,或是二者皆备。
何为准确,何为精确
维基百科上有关于准确和精确的很棒的解释,堪称经典词条。这里我用汉语向它致敬:准确是指现象或者测量值相对事实之间的离散程度小,也就是我们口语的“接近事实、符合事实”等;精确是指在条件不变的情况下,现象或者测量值能够低离散程度的反复再现,也就是我们口语说的“次次如此、回回一样”等。下面这两个图特别经典,从维基百科引用而来:

图1:这是指相对较高的准确度,但相对较低的精确度
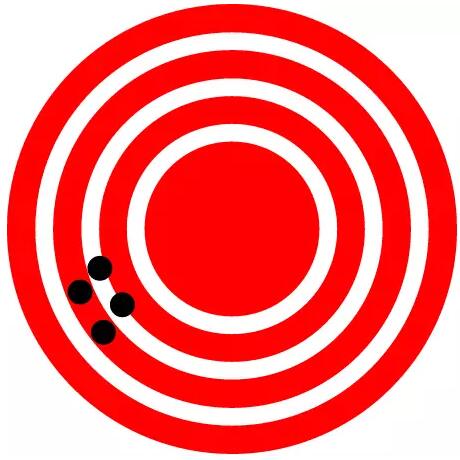
图2:这是指相对较高的精确度,但相对较低的准确度
上面的两个图中红色的圆心代表着事实。可以看到,在图1中,测量值围绕着圆心,虽然分布离散,但可以看出它们的平均分布位置肯定在圆心中(或者说,多次测量值的平均值是符合事实的),所以可以称为准确,但因结果离散而不能称为精确。在图2中,测量值明显偏离圆心(测量值的平均值也不可能在圆心上),所以不能称为准确,但可以称为精确,因为测量值的复现离散度很低。这是对准确和精确的极好解释。
如果我们把准确和精确作为两个不同的维度建立矩阵,可以得到下面的图:
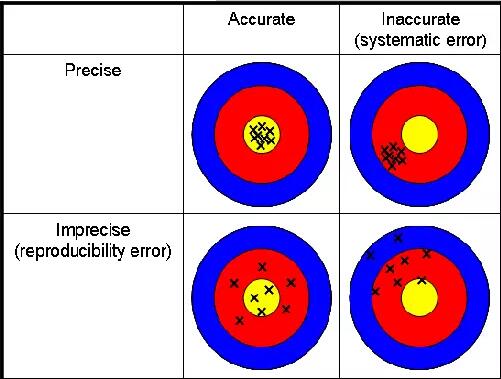
图3:准确和精确矩阵
左上象限是我们最喜欢的,既准确,且精确——对物理学和绝大多数理工科的要求就是如此;右下角是最糟糕的情况,不仅不精确,而且不准确——这是生活中最常见的,我们的社会生活其实很离散也很混沌。
那么,自然而然的你会问,互联网运营分析属于哪个象限呢?一定是左上角的象限对吗?
互联网运营分析是准确的吗?
首先,这个问题没有固定的答案,因为互联网运营分析(典型的如网站分析)的准确度很大程度上取决于你的期望和所采用的监测方法和所使用的工具。不过,就我们最常使用的分析方法而言,互联网运营分析绝对不属于图3中左边的两个象限(即不属于既准确又精确的象限,也不属于准确但不精确的象限),更简单说,就是它分析的数据不会准确。
这可能会让你失望,但相信并不出乎你的意料。你肯定已经发现,如果我们使用不同的网站分析工具衡量同一个网站的时候,各工具的结果之间有令人费解的差异(我在我博客www.jiaodaseo.com的文章为什么两个监测工具报告中的数据不同有探讨个中原因),而且我们也无法知道哪个工具是更准确的还原了事实上的数据。
所以,如果运营分析工具报告显示你的网站在一个月内有36,954个Unique Visitor,你的网站的真实访问者(一个个活生生的网友!)肯定不是36,954个!
事实上,我们几乎找不出来任何一个能够准确被统计的度量,即使是最基本最简单的度量——Page View也是如此!
因此,如果你的老板想要100%没有误差地知道网站到底有多少个人访问过,这个想要本身已经没有意义。
为什么运营分析数据无法准确
你可能会吃惊,因为我们的物理学实际上也是不可能100%准确的,原因是我们都听说过的“测不准原理”(事实上物理大部分时候当然可以100%准确,但到了微观世界,测量本身会影响测量对象,这才造成了无法真正100%准确,而只能了解微观粒子状态的概率)。同样,互联网运营分析也因为一个最基本的事实而无法准确,即:分析的监测媒介是浏览器、移动设备和服务器,而不是真实的人,这注定了我们不可能寻求到准确的结果。
具体而言,就目前我们通常使用的两种监测方法——Server Log和Page Tag都不可能准确对网站分析的一些最基本度量进行计数。
Server Log的误差(Bias)
Unique Visitor的误差:
如果用Server Log的方法监测数据,那么很显然,获取真实的访问者数量是不可能的任务。本身Server Log对于访问者的估算只能依据误差巨大IP,而网络爬虫/机器人的访问又使这种误差进一步扩大。
Page View的误差:
本来Server Log是可以很准确的记录Page View的,但是可惜Cache的出现让这成为历史。Cache极有可能会屏蔽服务器端的响应,这样Server Log可能不会留下任何关于某次Page View记录。
时间记录的误差:
在没有Cache干扰的情况下,服务器能准确探知访问开始的时间,但是访问结束的时间无法了解。因为访问结束往往是随关闭浏览器而一同结束的。关闭浏览器本身不能激发一条新的Server Log记录。
JavaScript、H5等客户端交互站点误差:
如果一个网站主要构成部分是包含多个页面的一个Javascript或者HTML5界面,或多个此类元素的组合,那么Server Log不会记录页面内部的操作,监测会几乎失效。解决这个问题的方法只能是在这些元素后面额外加上更多的监测代码。
Page Tag的误差
Page Tag失效:
Page Tag失效是会发生的。首先,一部分浏览器(例如手机上的一些浏览器)不支持JavaScript或者被设置为JavaScript禁止。其次,Page Tag可能会因为它之前的JavaScript出错而无法运行。再次,我们也看到过因为变量名冲突而发生Page Tag和页面上其他JavaScript冲突而无法运行的案例。最后,受网络速度的影响,页面上的Page Tag没有完全下载,浏览器就可能被人为关闭或者直接链向一个新的页面。
显然,如果Page Tag失效,那么网站分析工具就会失去部分或者全部数据。
Page Tag的位置:
Page Tag在页面中的位置会影响网站分析工具的计数。如果Page Tag在页面的上端,那么它会更快的被执行,受到其他因素(例如Page Tag之前其他JavaScript失效或者网速问题)干扰的情况就越小,计数也就会因此增大。Stone Temple Consulting的统计表明,代码在上的情况下,Visitor计数比在页面下的多4.3%。
Unique Visitor的误差:一个计算机可能被多人使用;一个计算机可能有多个浏览器(造成访问同一个网站有多个Cookie);人们会删除Cookie;Cookie被禁用。
Page View的误差:主要由Page Tag失效引起。
时间记录的误差:同Server Log一样,Page Tag能够准确记录访问开始的时间,但是结束时间无法了解,因为一般情况下访问的结束并不会触发Page Tag的执行。
由于诸如Page View,访问者和访问时间之类的基本的度量实际上是无法准确记录的,因此其他一些更高级的度量,例如我们常用的复合度量(Bounce Rate,Avg. Time on Site)就更不可能准确了。不过,知道了这些误差产生的原因,有助于我们进一步修正误差。有些监测工具(例如DCM,一个广告监测工具)具有自修正功能,就是利用了这个原理。
其他监测方法的误差:
互联网分析的其他获取数据的方式——比如通过客户端的软件搜集数据(Alexa,iResearch等),以及Sniffer(包嗅探)——则因其本身的监测方式所限,会有更大的误差。例如,通过客户端来搜集数据,很显然存在样本量的偏差;而Sniffer本质上是Server Log方式的翻版,但却增加了包丢失以及数据记录有限的问题。它们不可能比我们前面的两种方法更准确。
移动端的情况:
朋友们会问,上面讲的都是PC端,移动端的情况会好一些吗?移动端在识别人的唯一性上确实比PC端有更多的优势,比如,安卓系统可以使用IMEI来标识唯一的人,苹果端也可以用IDFA。这些标识一般会跟着一个设备“走一辈子”。不过IMEI本身并不是百分之百准确,如果这个世界上不存在水货机、翻新机,而全部是经过工信部认证批准的通信设备的话,那么IMEI是最靠谱的。但我们在中国,水货泛滥,翻新机也很多,这些来路不明的手机的IMEI就有可能是人为修改的。所以很多手机共用一个IMEI号码,或IMEI号码都是0的情况就很多了。因此IMEI号码也不是十全十美。
苹果的IDFA呢?大部分人都不知道苹果有这个东西,所以也就不会去关闭或者刷新这个东西。目前看起来IDFA比IMEI要更好,但仍然有少部分人会真的去关闭它。
总体看移动端辨识唯一的用户比PC端靠谱。但移动端也有很大的短板,不像PC端Web监测流量来源那么容易,移动端APP想监测它们的下载来源——不仅仅是用户从什么应用商店下载,更是用户从什么地方发现了这些APP而进入应用商店的来源——是很困难的。我们确实有不少方法可以实现对于APP下载来源的监测(至少有3种方法,我的培训有讲到),但每一种都无法保证准确,而且每一种都无法保证所有的渠道都能够被cover到。
我认为移动app的监测除了在用户唯一性识别上优于web,其他的都可能比web更不准确。
分析工具精确吗?
现在,你知道了分析工具并不能准确计数。那么,分析工具精确吗?
我要说,精确是分析工具的必备特征,分析工具做不到准确,但必须精确。如果某个分析工具不精确,那么它就与垃圾无异。
分析工具必须精确的原因很简单,因为我们需要数据具有高度的一致性。如图4(下图)所示,如果分析工具的精确度存在-20%到+20%的误差,那么假设11月4日的网站准确流量是50个UV,分析工具所报告的数值可能是40和60之间的任何一个数。同样,我们假设次日(11月5日)的网站准确流量是51个UV,那么网站分析工具所报告的数值可能是41到61之间的任何数。那么,因为存在不精确,那么11月4日的数据有可能最终呈现40,而11月5日的数据则完全可能被最终呈现为61,这样分析工具会误报出一个令人满意的增长——但事实上这个增长并不存在。反过来,如果11月4日的数据被报为60,而次日被报为41,那么更糟糕,这与实际情况是完全相反的。
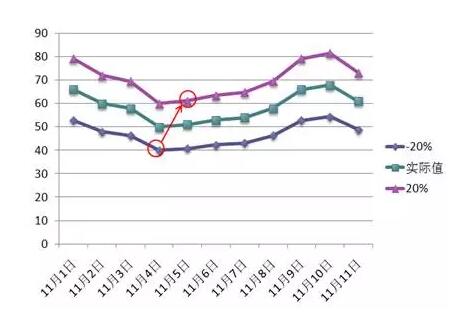
图4:如果网站分析工具不精确会产生严重后果
因此分析工具必须精确,如果它与事实有-20%的误差,那么不论是哪一天哪一刻,它都必须比准确值小20%。否则我们就会得到错误的结论。当然,100%的精确也是不存在的,一般而言,允许+/-5%左右的系统偏差,这一来一去其实已经有最大10%的分离度,实际上已经是非常宽的标准了。
分析工具不能做到100%精确的原因其实也是受跟上一节的那些因素一样的影响,另外还有一些访问者或者用户所处环境的变化造成的未知异常,例如网络带宽的变化或是数据传输过程中的异常丢失等。
如何面对分析工具的不准确但精确的特性?
分析工具不准确但精确的特性不妨碍我们获得真正的insight(见解)。我们需要遵循三个分析的基本原则:
原则一:趋势。
看趋势而不是看孤立数据是分析最重要的原则。你不可能因为网站或app今天的流量是500个而狂喜,但是如果上个月的平均流量是300,而这个月的平均流量是500,那么我会恭喜你,你也值得高兴一番。我们在以前的文章中对这个有讨论哦。
由于分析工具是精确的,因此虽然不能准确反映数据,却能够准确反映趋势。这也是我们所有的分析师会认为趋势是最重要的方法论的原因。
原则二:细分。
因为分析工具的精确性,如果整体值比实际准确值偏小20%的话,那么构成整体的各部分也会同比比各自的准确值偏小20%。因此,比较所需要的细分仍然能够满足分析的需要。
原则三:转化。
与细分类似,精确性能够保证转化是同比放大或缩小,因此转化本身的比例是准确的。
如此看来,我们最后要得出的结论是:真正帮助我们进行分析的关键方法所需要的数据是精确的。因此,当我们理解并且学会运用分析的三原则之后,我们有可能把网站分析工具所在的象限转移到左上角的象限——即既准确且精确。真的,分析工具最终准确与否,在于你是否用好了它,这是唯心的结论,但确实是真正的真相。
 鲁公网安备37131102371371号
鲁公网安备37131102371371号