

百度技术委员会理事长陈尚义对腾讯科技解密,称百度成立之初就开发了自己的大数据存储系统。团队云集包括谷歌、IBM、微软等数据存储和处理方面专家。他还透露,百度未来将开发跨数据中心存储系统。
陈尚义介绍,百度每天面对海量数据。每天收集几千亿网页,系统每天都产生海量日志,容量达到百PB级,需要数万台服务器存储,这还不算用户在使用百度产品中自己生成的内容(UGC)和百度客户数据,这部分数据加起来就有几个PB,仅这些数据就比传统企业的大上很成千上万倍。并且随着网页资源增加和搜索质量提升,网页和超链数据将随之急剧增加。
百度数据呈现海量、高增长,结构化和非结构化大量并存,记录大小差距巨大,数据一致性强弱不一,数据冷热不均,突发事件常导致数据访问波峰等特点。与此同时,百度业务对数据存储和处理提出极高要求。要求数据高可用、高可靠、高通量、高时效、高并发、高可扩展,要求百度的数据存储能力和处理能力必须以非常简单的方式获得扩容,以降低维护升级的代价。面对这些特点和要求,百度必须开发自己的大数据存储系统。
陈尚义说,百度最早上线数据存储系统时,开源系统还没有发布,还由于开源系统的性能受限、无法充分利用机器的各种资源尤其是新硬件资源、无法为特定的访问模式做优化、缺乏满足工业界的稳定性等诸多原因,百度不能使用开源系统。不仅开源的用不上,而且市场上无现成商业化产品可供百度使用,因为任何一个厂商都没有如此海量、如此复杂的数据。
百度一开始就自主开发了大数据存储系统,用于存储网页和超链、客户信息和用户产品、系统日志等海量数据,支持Table、Pipe、File和KV等数据类型,满足百度业务的流式和触发式计算、文件存储和访问、低延迟、高并发的需求。
陈尚义说,在这些基础上,百度还面向广大网民推出云存储系统,在前不久发布的百度易手机上,每个用户可拥有100G的免费存储空间。除了给每个用户100G的免费空间外,百度易手机上应用和数据,都是这套系统在背后支撑。
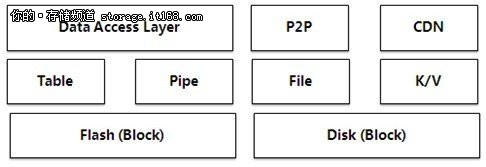
▲百度大数据存储体系
陈尚义还透露,为应对上百PB的数据,满足诸多近乎苛刻的要求,百度采取了一些措施。包括开发网页更新模型,将对磁盘的随机写转化为批量的顺序写,提高数据的写入速度,缩短了网页数据的更新周期,提高搜索引擎等产品时效果性。
此外,还包括对涉及数据存储和访问的各个方面进行全局优化。对访问模式采用数据索引、缓存热点数据、外存预读、IO缓存等技术手段,降低在线访问的延迟,提高系统的吞吐量;未来,百度还将开发跨数据中心的存储系统。
 鲁公网安备37131102371371号
鲁公网安备37131102371371号